
Fine-tune Llama 2 model on SageMaker Jumpstart
In this tutorial we will learn how to Fine-Tune Llama-2-7b model on Amazon SageMaker Jumpstart.

In this tutorial we will learn how to Fine-Tune Llama-2-7b model on Amazon SageMaker Jumpstart.
Launch SageMaker Studio and perform the following steps:
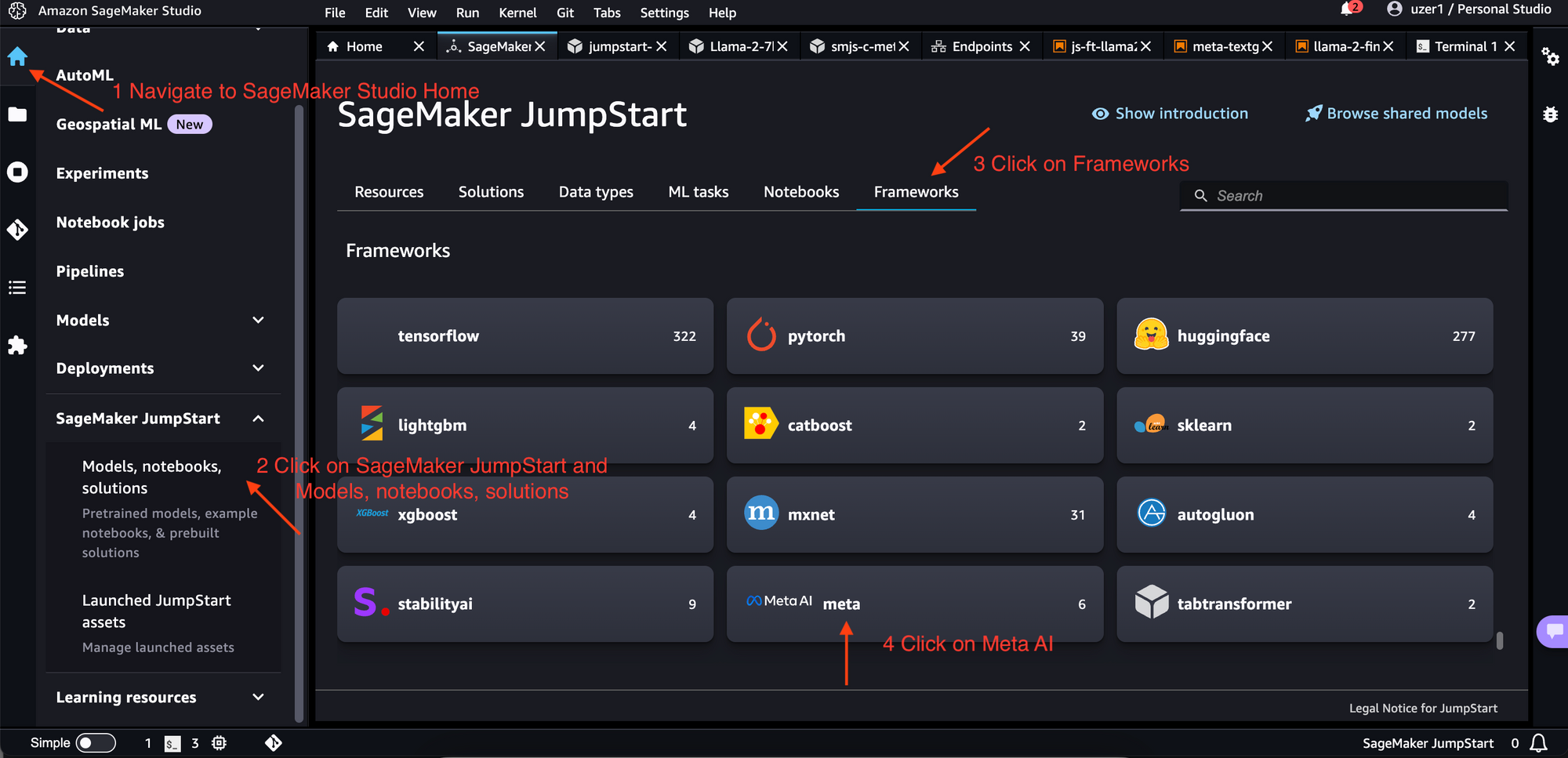
- Navigate to SageMaker Studio Home
- Click on SageMaker JumpStart and Models, notebooks, solutions
- Click on Frameworks
- Click on Meta AI
Since we are looking to finetune the model, choose the model that is fine-tunable. The chat models available via SageMaker Jumpstart at the time of writing this tutorial are not fine-tunable.
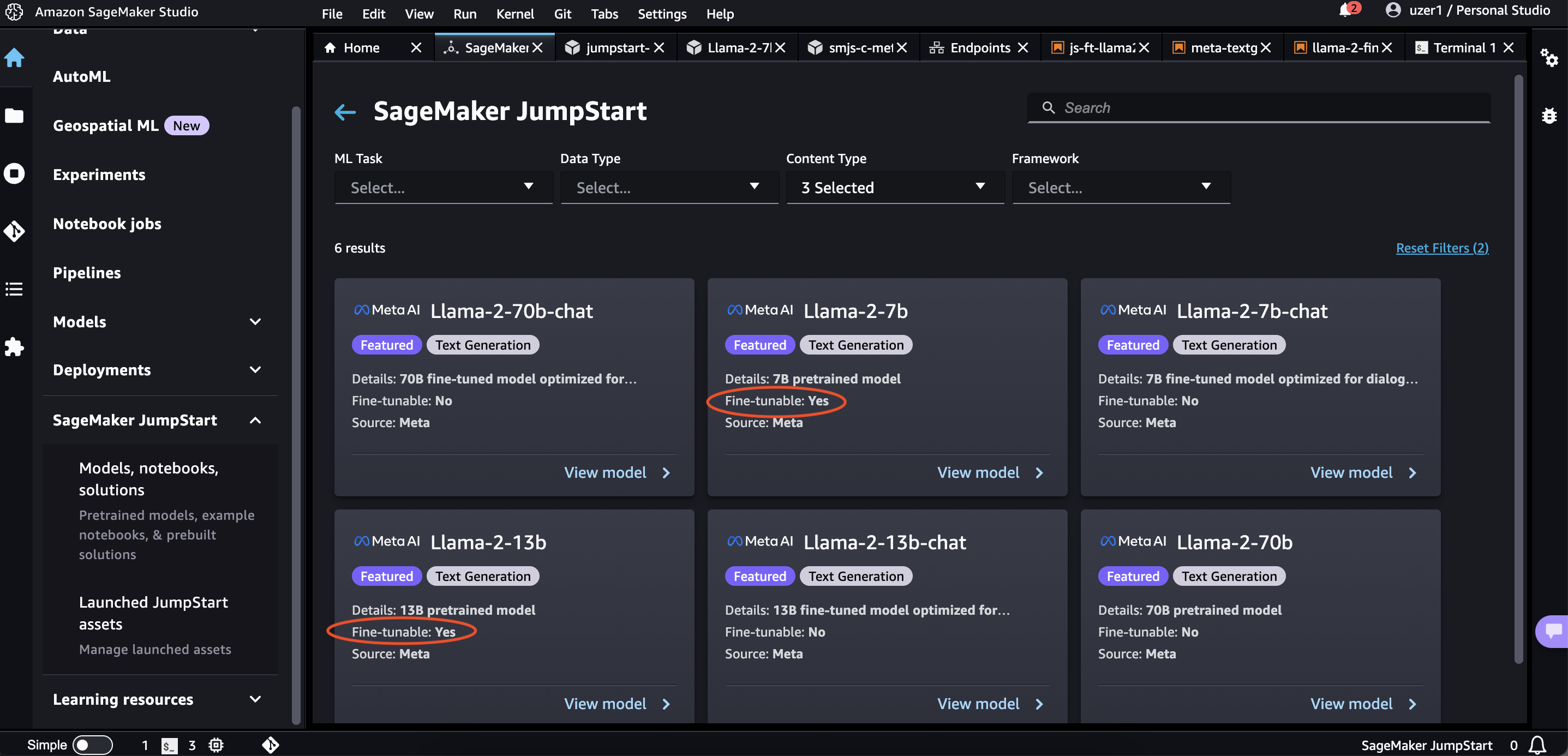
Since we are just learning, choose Llama-2-7b.
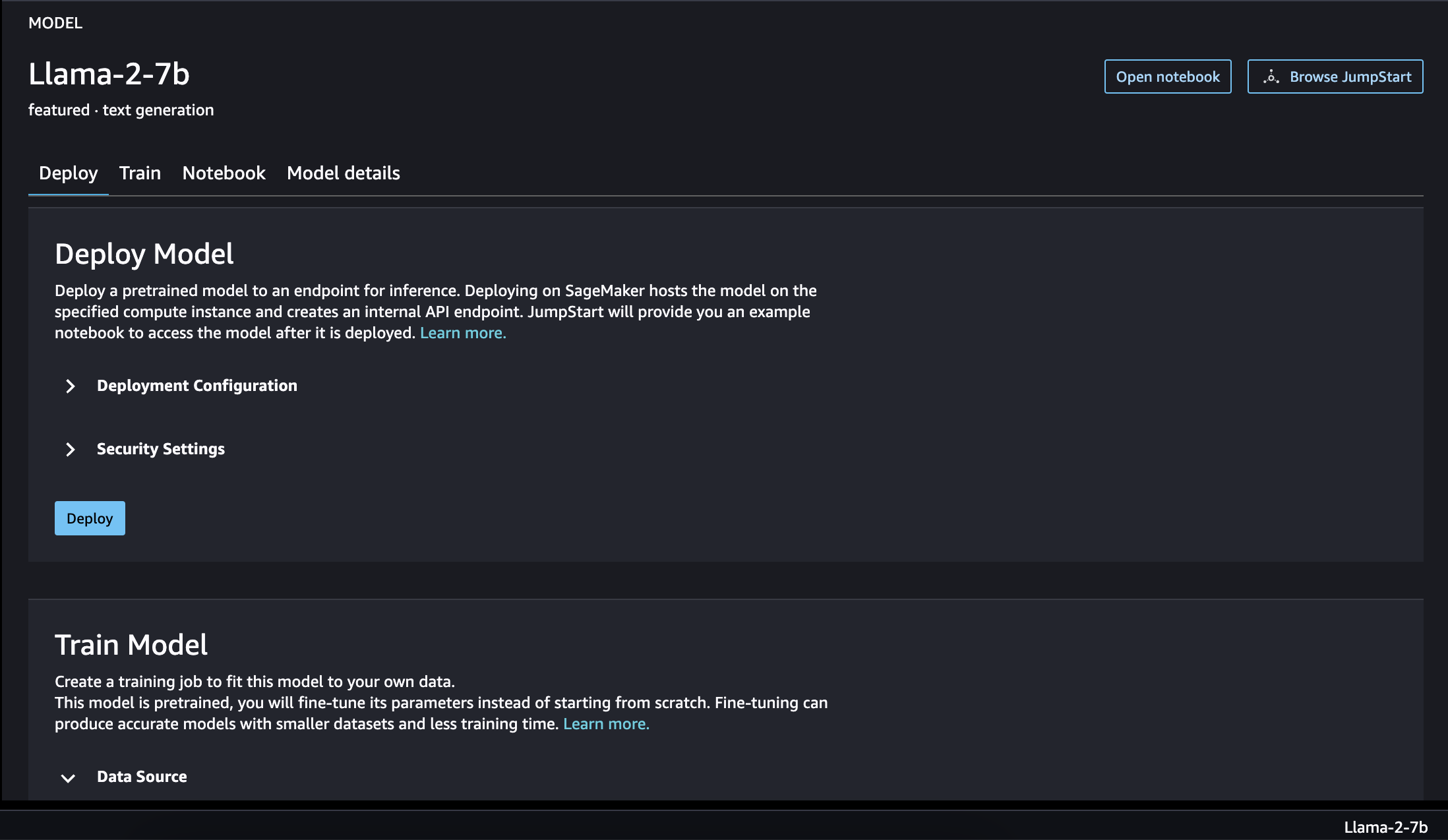
Once you choose the Llama-2-7b, you will land on UI that offers you options such as Deploy, Train, Notebook, Model details.
Dataset preparation
We will use Dolly Dataset to fine-tune Llama-2-7b model on SageMaker JumpStart.
Run the following code to create dataset for training and evaluation
from datasets import load_dataset
dolly_dataset = load_dataset("databricks/databricks-dolly-15k", split="train")
# To train for question answering/information extraction, you can replace the assertion in next line to example["category"] == "closed_qa"/"information_extraction".
summarization_dataset = dolly_dataset.filter(lambda example: example["category"] == "summarization")
summarization_dataset = summarization_dataset.remove_columns("category")
# We split the dataset into two where test data is used to evaluate at the end.
train_and_test_dataset = summarization_dataset.train_test_split(test_size=0.1)
# Dumping the training data to a local file to be used for training.
train_and_test_dataset["train"].to_json("train.jsonl")
train_and_test_dataset["test"].to_json("test.jsonl")The sample structure of one jsonline entry of train.jsonl looks as follows:
{
"instruction": "Your Instruction question goes here?",
"context": "YOUR Lengthy Context goes here",
"response": "Your response goes here"
}Also we will be doing instruction fine tuning. So we will define the template that holds instructions for each jsonline.
import json
template = {
"prompt": "Below is an instruction that describes a task, paired with an input that provides further context. "
"Write a response that appropriately completes the request.\n\n"
"### Instruction:\n{instruction}\n\n### Input:\n{context}\n\n",
"completion": " {response}",
}
with open("template.json", "w") as f:
json.dump(template, f)As we want to fine-tune the model, click on Train Tab and let's proceed with training.
At this point you will have three files. Two files in json lines format and one template file in json format.
- template.json
- train.jsonl
- test.jsonl
Upload the template.json and train.jsonl to a directory named train (this could be any name but for identifying we are naming it training) in the s3 bucket (or default s3 bucket associated with sagemaker)
Upload the test.jsonl file to directory named evaluate in the s3 bucket.
Ensure the S3 bucket is in the same region as your sagemaker domain you are performing the activiy of fine-tuning.
We will see how to use these files as we proceed to UI based fine-tuning of Llama-2-7b via SageMaker JumpStart
Training
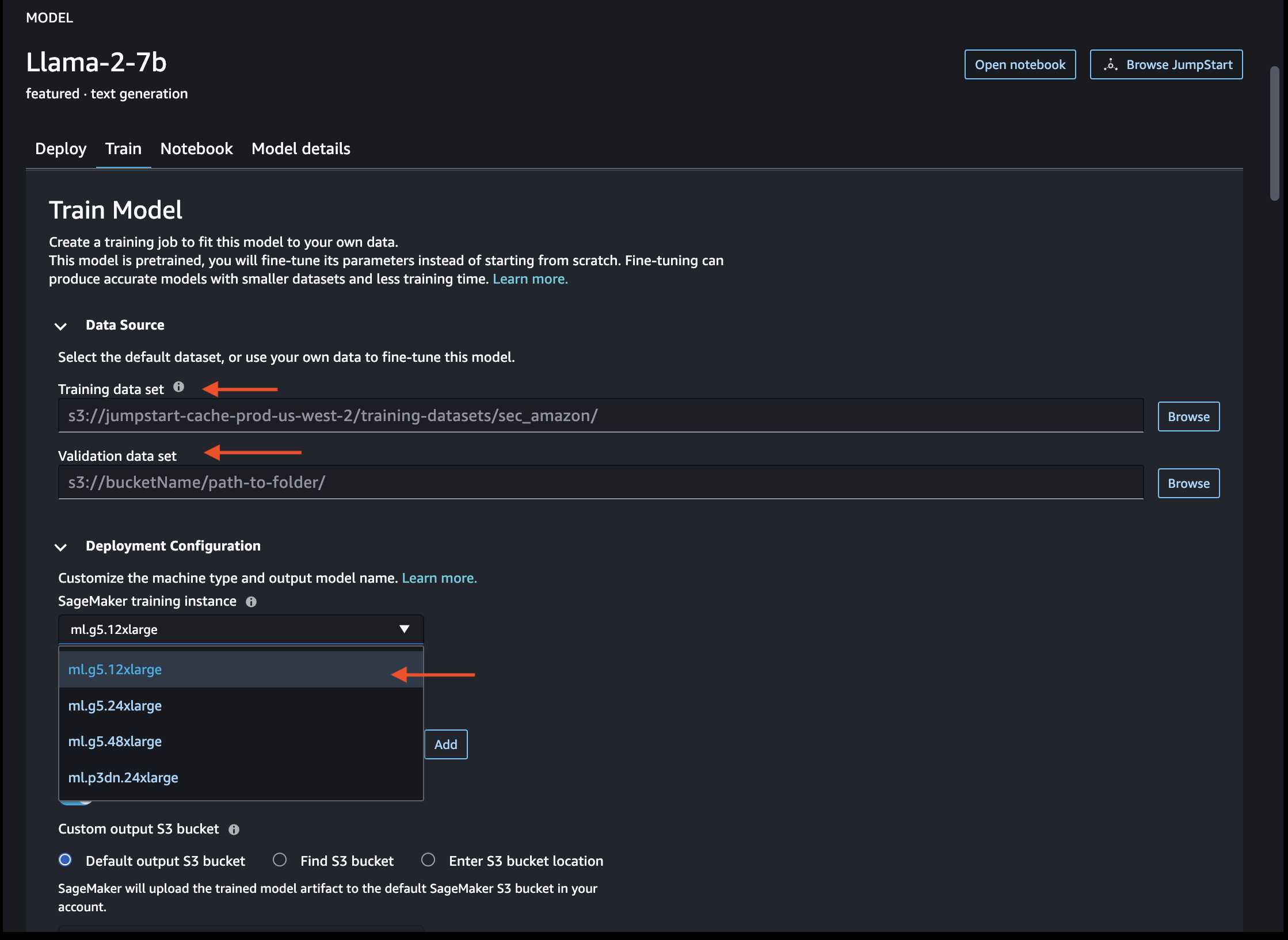
Provide Training data set S3 URI and Evaulation data set S3 URI. Also choose the instance type for traning. For the sake of demonstration I'm choosing ml.g5.12xlarge which is the least possible instance type I can choose among other high end ml instances which include ml.g5.24xlarge, ml.g5.48xlarge and ml.p3dn.24xlarge. If you want to choose the higher end instances such as p3dn, ensure you have quota alloted or you can request for quota to allot those instances.
Hyperparameters:
I have choosen the following Hyper parameters:
Enable FSDP: True
Epochs: 5
Instruction-train the model: True
Int 8 quantization:False
Learning rate: 0.0001
Lora alpha: 32
Lora dropout: 0.05
Lora r: 8
Max input length: -1
Maximum train samples: -1
Maximum validation samples: -1
Per device evaluation batch size: 1
Per device train batch size: 4
Preprocessing num workers: None
Seed: 10
Train data split seed: 0
Validation split ratio: 0.2
You can choose the hyper parameters according to your criteria to get best fine-tuned model.
Security Settings: I have left default security settings, but be cognizant about the security when it comes to mangaging your fine-tuning of LLM. You can choose to select the traning to happen in a VPC in the subnet you define under strict privacy controls.
Initiate Training
Once everything is configured, click on Train to initiate training.
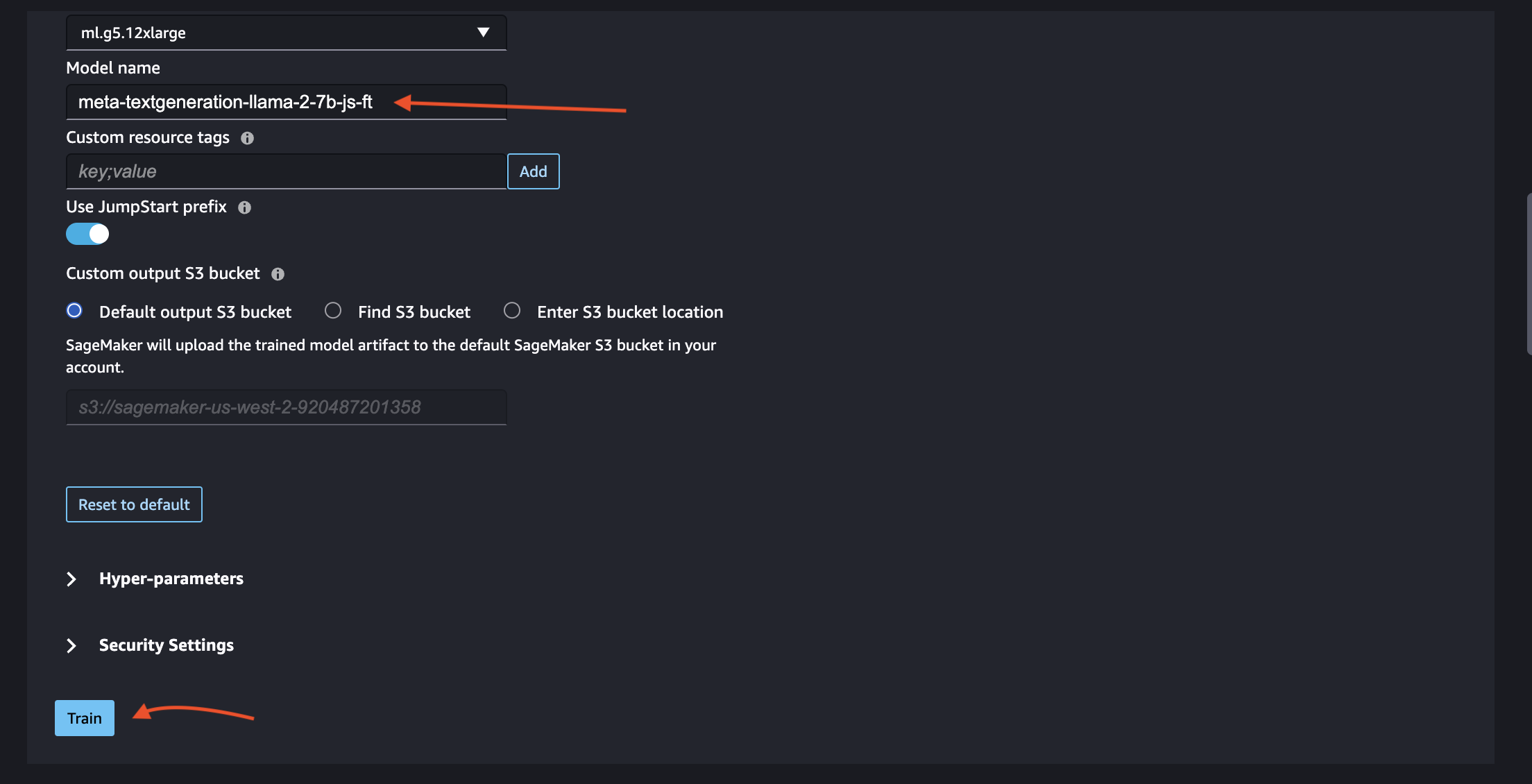
Click on training to initiate the training.
One the training is initiated, you will start seeing Logs.
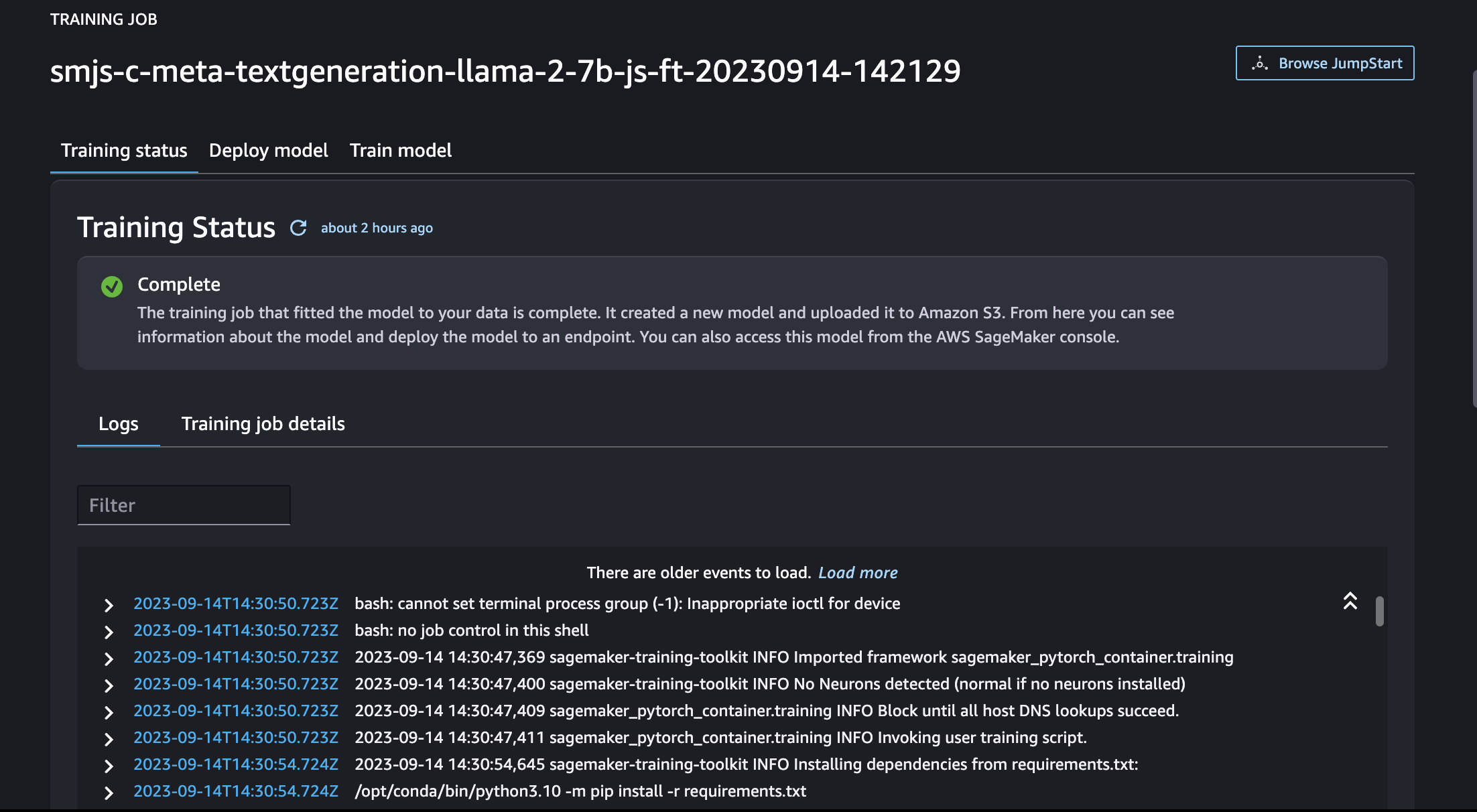
You will see the Traingning status Complete with green check mark as shown below.
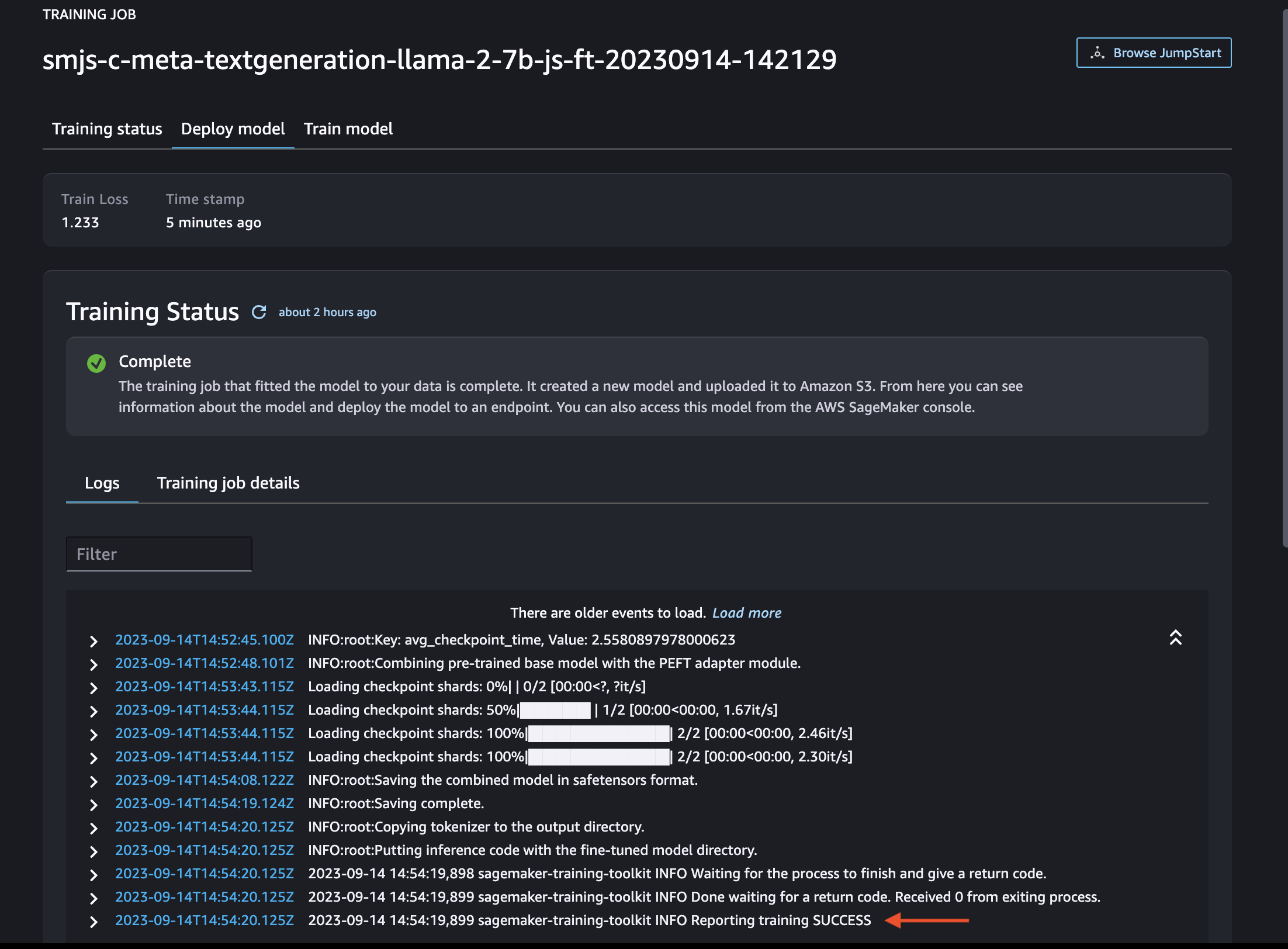
You can also notice in logs, once the training succeeds, you will see the log entry INFO Reporting training SUCCESS at the end of the Logs.
Notice the following details by navigating to Training job details tab.
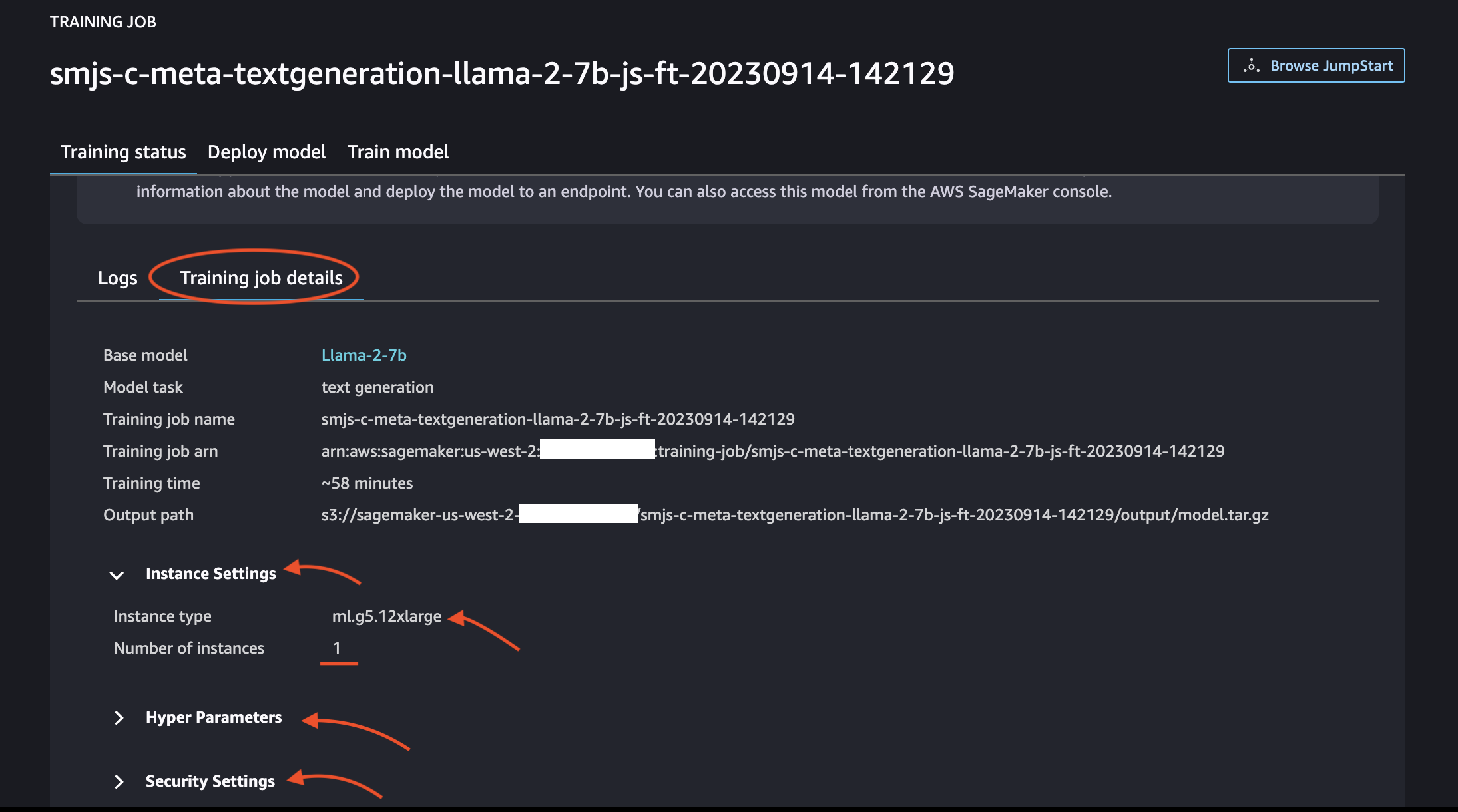
You can notice above that the training time ~58 min. It is purely subjective to the various factors but not just limited to the ones mentioned below:
- Size of training and evaluation data
- Hyper Prameters
- Instance Type chosen for fine-tuning
Deploy the Fine-Tuned model
After the fine-tuning is done, from the same Training job window, scroll down further to find the Deploy button.
Similar to Fine-Tuning, you have the liberty to choose the Deployment Configuration. I'll be proceeding with ml.g5.2xlarge which is fine for Llama-2-7b.
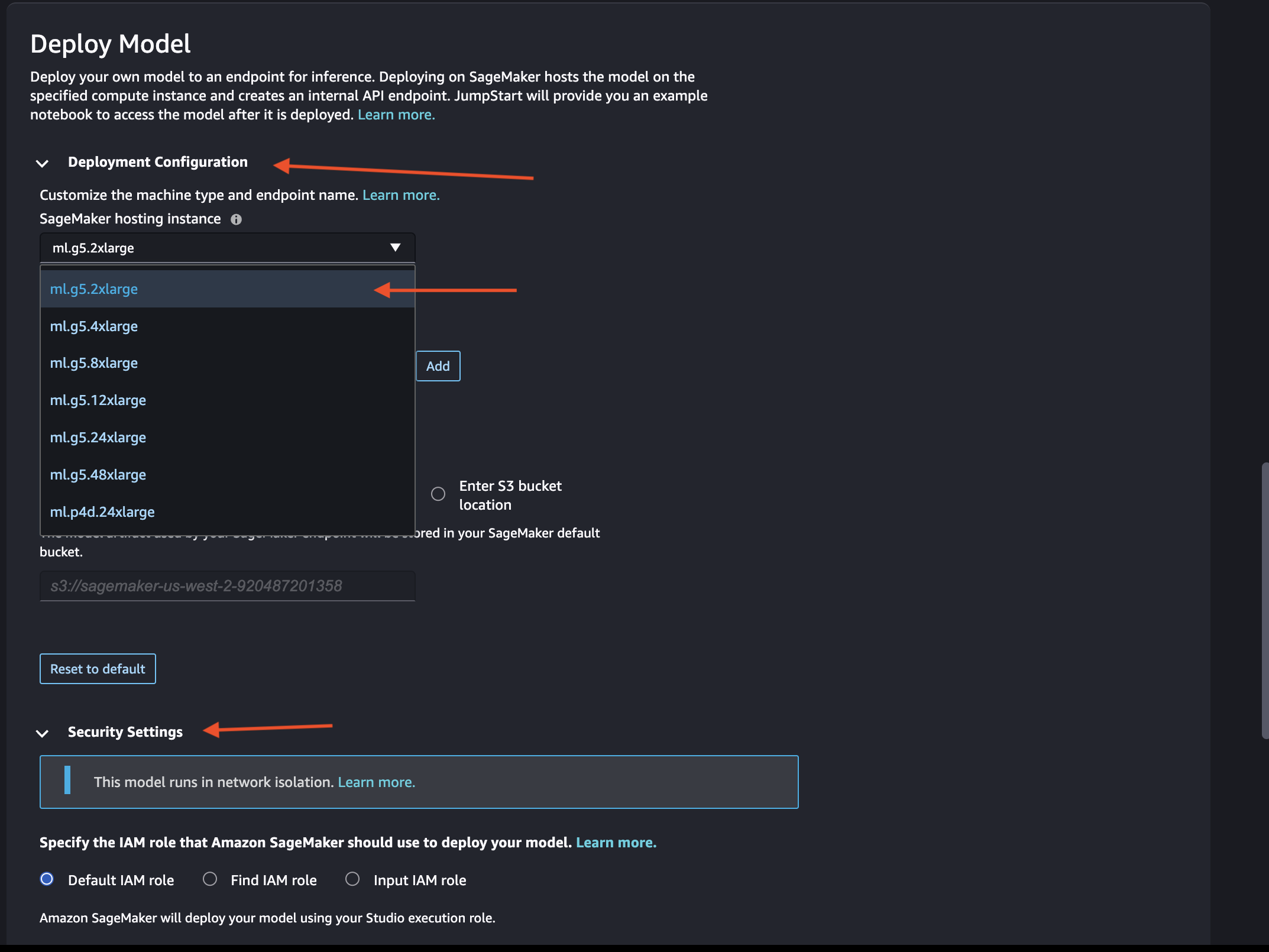
For the sake of tutorial, I'll go with defualt IAM role under the Security Settings. But you may want to specify to ensure you have proper privileges and security guard rails in order to invoke the deployed SageMaker Endpoint.
Click Depoly to initiate the deployment of fine-tuned model using the SageMaker JumpStart UI.
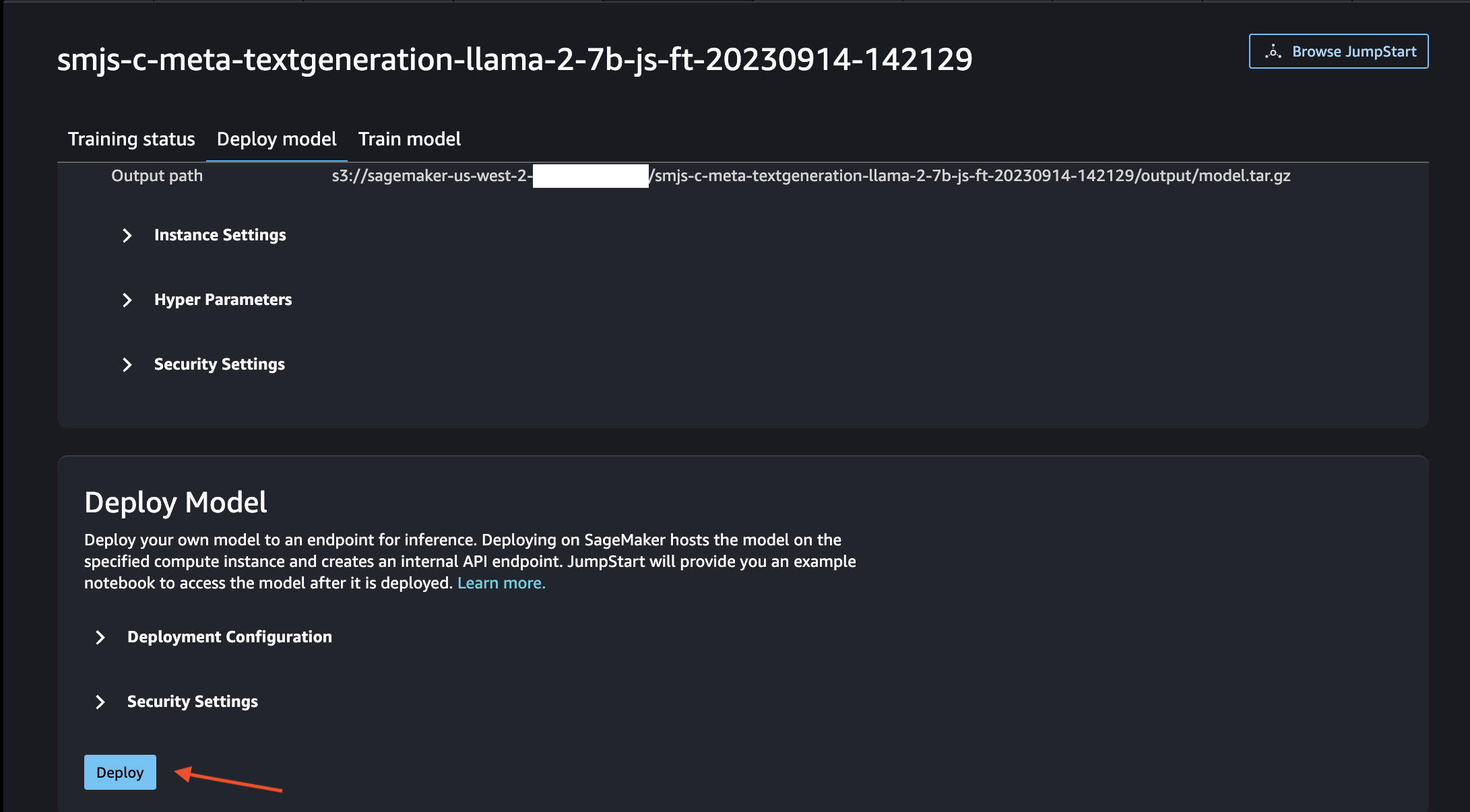
Deployment Status
Once the deployment is done, you will see the Endpoint Status as In service.
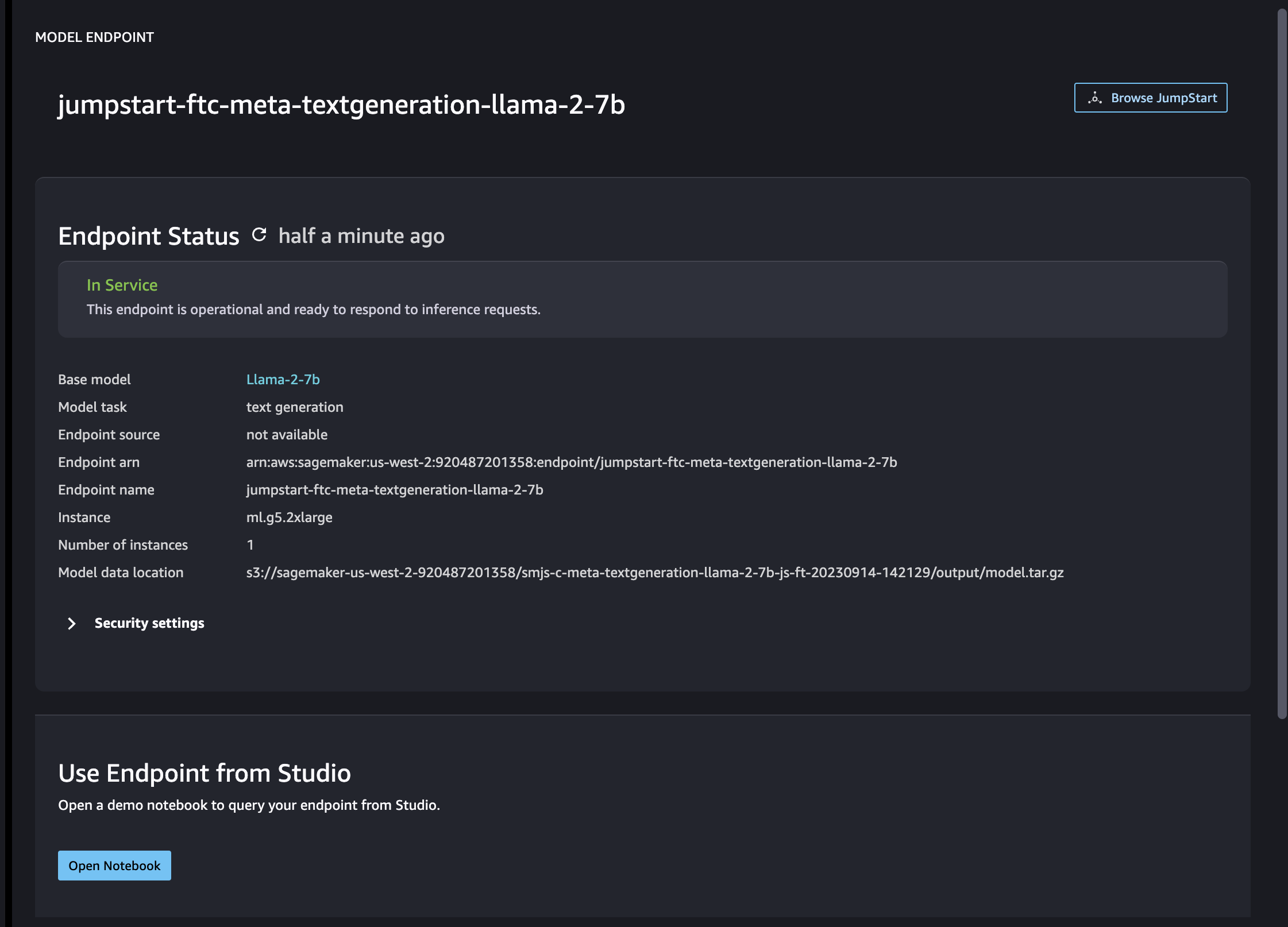
You can stay on the same tab or you can naviate to Deployments -> Endpoints to see the status of deployment of your endpoint.
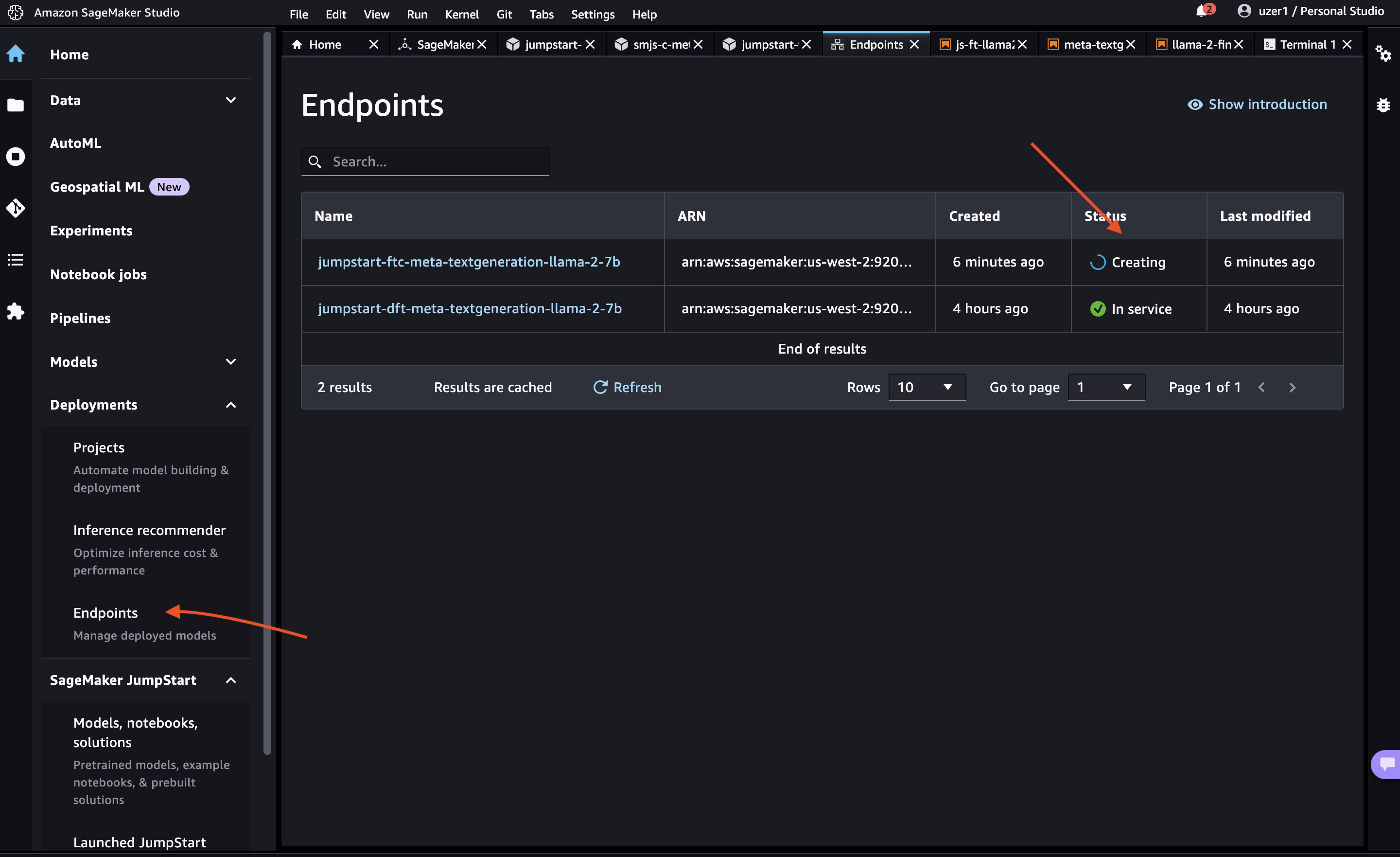
When you see the end-point status Creating, wait for it to trun into In service, that indicates the fine-tuned SageMaker endpoint deployed successfully and is ready for inferencing.
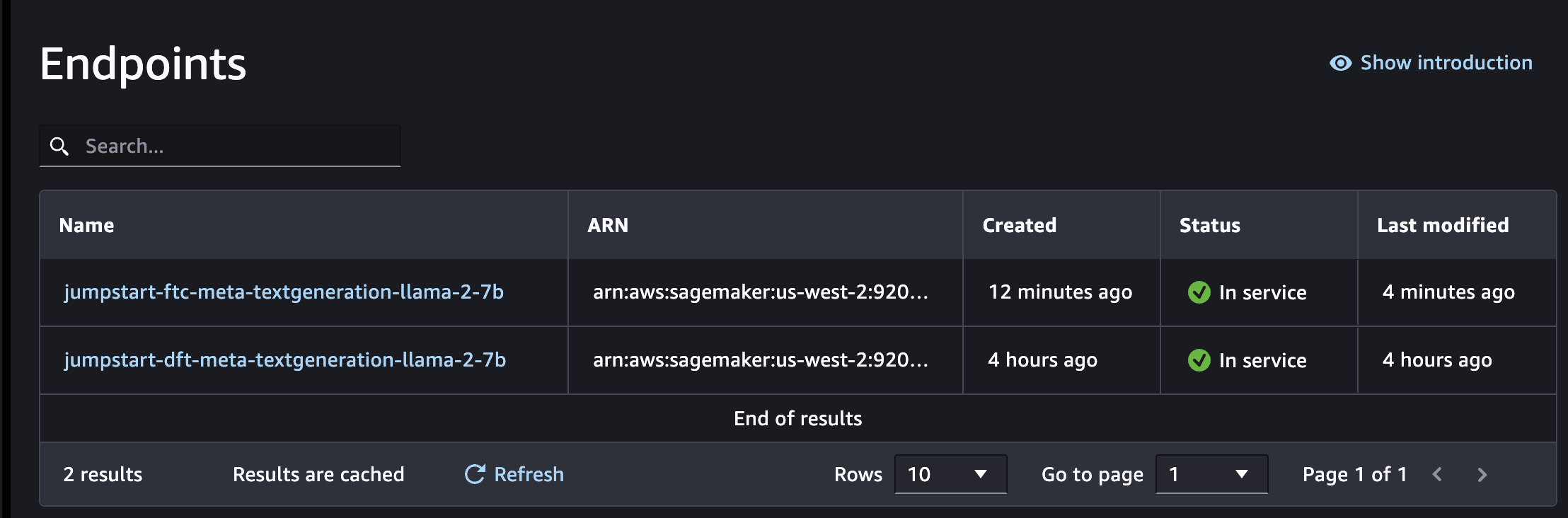
After successful deployment, you will see the status on Model Endpoint tab as In service as shown above.
Learn how to inference SageMaker endpont in this tutorial : How to Inference SageMaker JumpStart LLaMa 2 Realtime Endpoint Programatically
 admin
admin