
How to Inference SageMaker JumpStart LLaMa 2 Realtime Endpoint Programatically
In this tutorial we will inference LLama 2 endpoint deployed via SageMaker JumpStart UI from SageMaker Notebook.

You might want to refer to Fine-tune Llama 2 model on SageMaker Jumpstart, if you are looking to fine-tune Llama 2 model on SageMaker JumpStart.
 admin
admin
In this tutorial we will inference LLama 2 endpoint deployed via SageMaker JumpStart UI from SageMaker Notebook.
Launch SageMaker Notebook
Launch SageMaker notebook and choose the environemnt as detailed below.
For the sake of this tutorial I am using SageMaker Notebook with the Environment having the following kernel configuration:
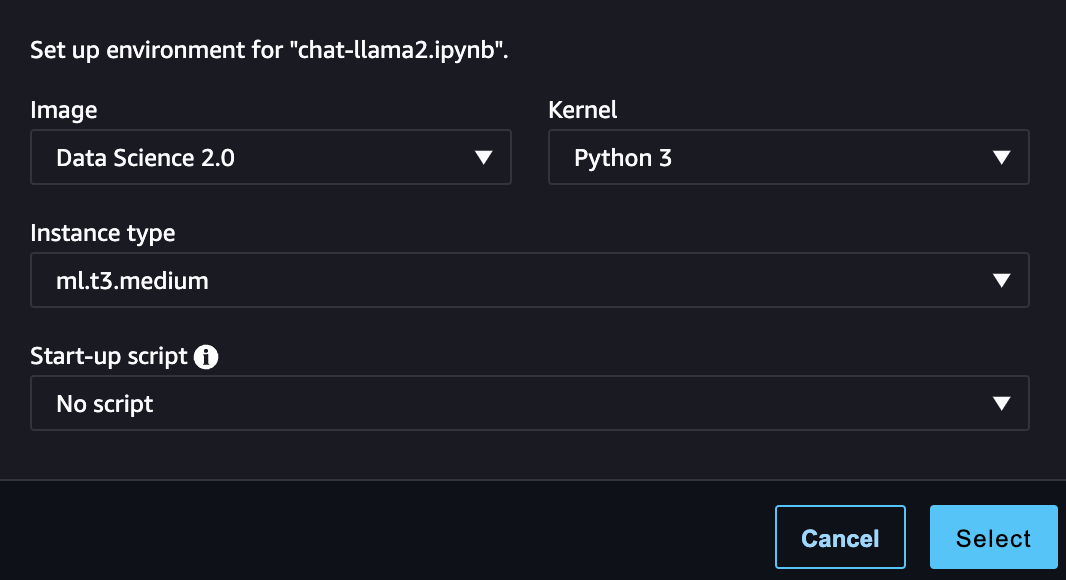
Since we are not doing any heavy data processing or training, as we are just invoking an sagemaker endpoint, an environemnt with the configruation having Image: Data Science 2.0, Kernel Python 3 and Instance type ml.t3.medium should be engouh for invoke the endpoint.
First let's upgrade sagemaker package for the notebook by running the following command
%pip install --upgrade --quiet sagemakerNow lets get the initial setup such as obtaining sagemaker execution role, boto3 and default bucket as follows.
import json
import sagemaker
import boto3
smr_client = boto3.client("sagemaker-runtime")Obtain the SageMaker Endpoint name by navigating to Home-> Deployments -> Endpoints section as shown below.
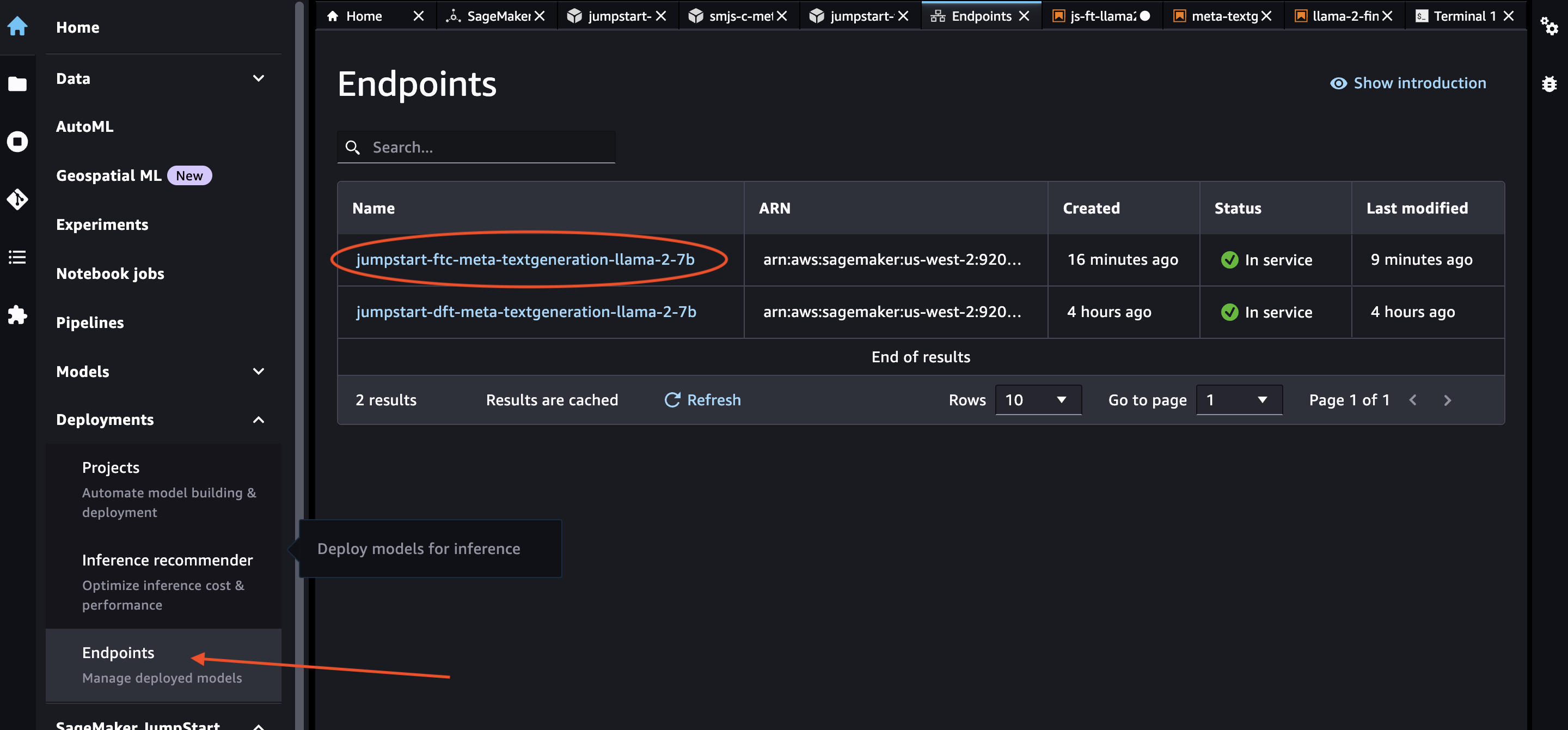
Now we will define invoke_endpoint that accepts payload arg as payload, sagemaker runtime client arg as smclient, and endpoint name arg as endpoint_name.
def invoke_endpoint(payload, smclient, endpoint_name):
res = smclient.invoke_endpoint(
EndpointName=endpoint_name,
Body=json.dumps(payload),
ContentType="application/json",
CustomAttributes="accept_eula=true")
return res["Body"].read().decode("utf8")We will now define the arguments as follows.
endpoint_name_ft = 'jumpstart-ftc-meta-textgeneration-llama-2-7b'payload = {
"inputs": "I believe the meaning of life is",
"parameters": {
"max_new_tokens": 64,
"top_p": 0.9,
"temperature": 0.6,
"return_full_text": False,
},
}The inputs can be any prompt that you want to send to Llama-2 or in case you are inferencing a fine-tuned SageMaker Endpoint of Llama-2 then the input will be relevant to the data that your fine-tuned model has context of.
Finally invoke the endpoint and print the results.
response = invoke_endpoint(payload, smr_client,endpoint_name_ft)
print(response)The response json will look something like follows.
[
{
"generation":" to be happy.\nThe meaning of life is to live.\nI think the meaning of life is to be happy.\nThe meaning of life is to live. I think the meaning of life is to be happy.\nThe meaning of life is to live. I think the meaning of life is to be happy"
}
]